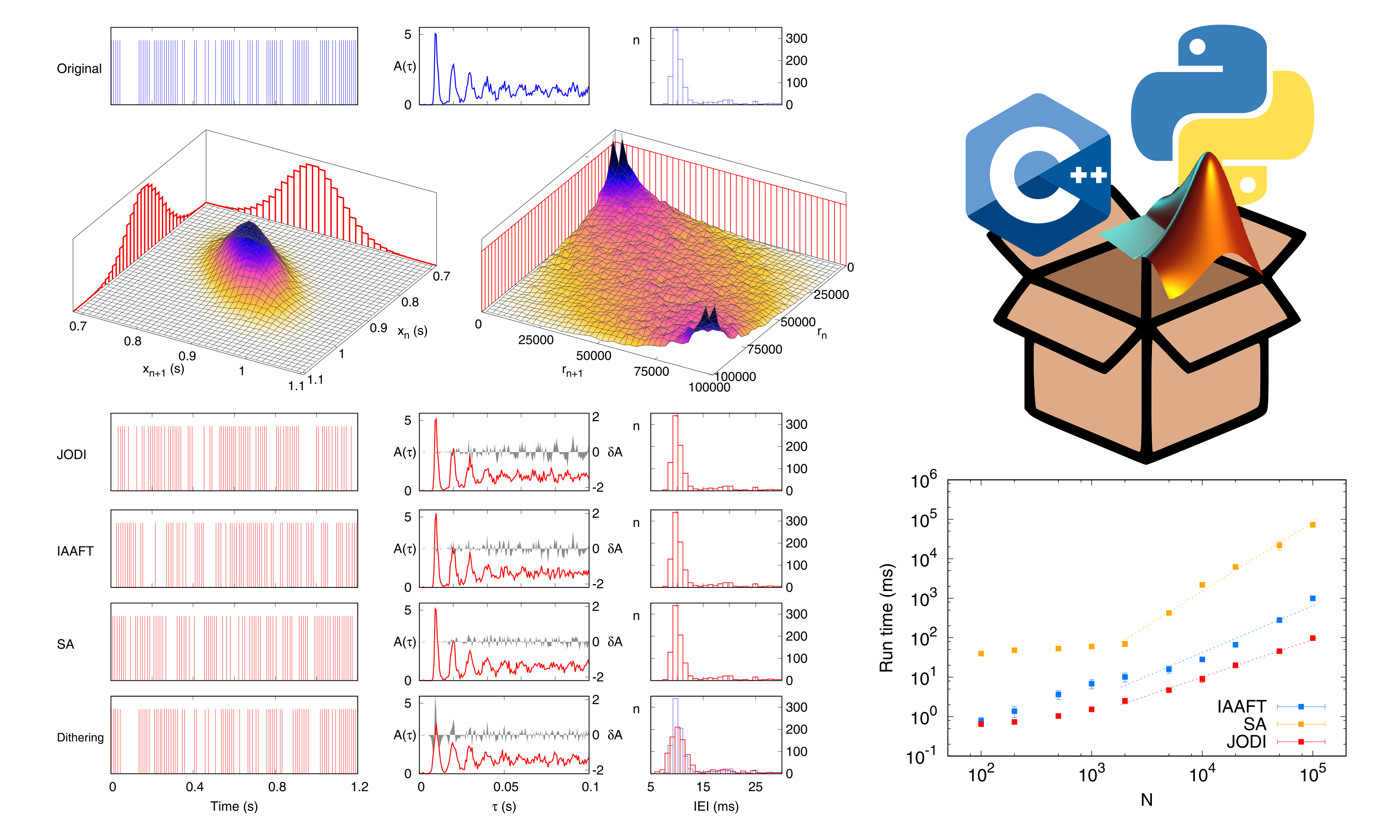
Lo studio di molti sistemi dinamici è basato sull'analisi di sequenze di eventi registrate sperimentalmente, in cui l'informazione è codificata negli intervalli temporali tra eventi. Una corretta interpretazione dei risultati prodotti dall'applicazione di tecniche di analisi richiede la valutazione della relativa significatività statistica. Nella gran parte dei casi, l'ipotesi nulla corrispondente è sconosciuta, impedendo quindi tale valutazione. Una soluzione alternativa, che è efficace nel caso di segnali continui, è data dalla generazione di dati surrogati che condividono proprietà statistiche e spettrali con i dati originali. Tuttavia, nel caso di sequenze di eventi, gli algoritmi disponibili per la generazione dei surrogati possono diventare di difficile applicazione e computazionalmente costosi. Pertanto abbiamo sviluppato un nuovo metodo, chiamato "JODI", per la generazione di serie surrogate di eventi, che si basa sulla distribuzione congiunta degli intervalli temporali tra gli eventi della serie. Il nostro metodo, testato sia su sequenze sintetiche che sperimentali, ha prestazioni, in termini di distribuzione degli intervalli temporali e autocorrelazione, tanto buone quanto i metodi convenzionali, nonostante abbatta il costo computazionale di almeno un ordine di grandezza. Il metodo è presentato in:
L. Ricci, M. Castelluzzo, L. Minati and A. Perinelli, Generation of surrogate event sequences via joint distribution of successive inter-event intervals, Chaos 29 (2019), 121102, doi:10.1063/1.5138250
In aggiunta, abbiamo sviluppato un pacchetto software che implementa quattro algoritmi per la generazione di serie surrogate di spikes e, più in generale, di eventi discreti. Oltre a JODI, il pacchetto implementa tre degli algoritmi più utilizzati, cioè IAAFT, annealing simulato, e dithering. Lo scopo del pacchetto è di fornire una serie di strumenti unificati e portabili per generare surrogati di processi puntuali. Il codice è fornito in tre linguaggi, C++, Matlab e Python, consentendo così di integrare le funzioni del pacchetto in gran parte delle pipeline di analisi. Il pacchetto SpiSeMe (Spike Sequence Mime), disponibile alla repository GitHub dedicata, è descritto in dettaglio in:
A. Perinelli, M. Castelluzzo, L. Minati and L. Ricci, SpiSeMe: A multi-language package for spike train surrogate generation, Chaos 30 (2020), 073120, doi: 10.1063/5.0011328